안냐세염. 까막임돠...
회사에서 업무를 수행하다 보니 나오게된 결과물 입니다. 유틸리티성으로 만들게된 것인데
상업적 사용만 아니라면 공개해도 문제 없다는 답변을 받고 올려봅니다.
(상업적 사용이란, 회사에서 가공없이 업무에 사용하는것은 상관없습니다만, 재가공 하여 판매하는 것을 말함)
(개인적인 욕심은 혹시 사용해보시고, 문제점이나 추가 기능에 대한 요구등을 얻을 수 있을까 하는 목적도 ㅎㅎ;;;)
제목 그대로 테이블만 별도 파일로 떨구거나, 혹은 수행한 쿼리문의 결과를 파일로 저장하는 기능
그리고, 반대로 저장된 파일을 다시 테이블로 넣는 기능을 제공하는 유틸리티입니다.
(파일로 쓰거나, 테이블에 로딩하는 속도는 select into 와 비교했을 때 뒤지지 않습니다.)
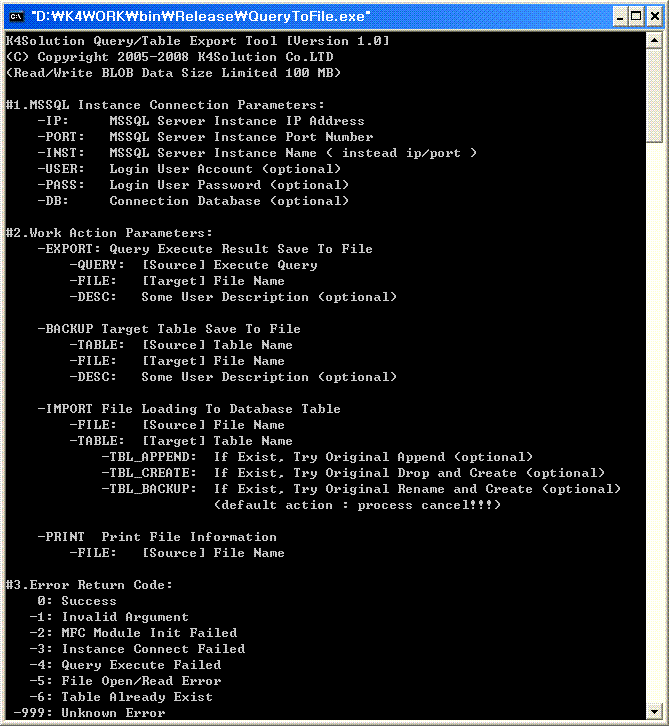
1. 알려진 사용상의 단점
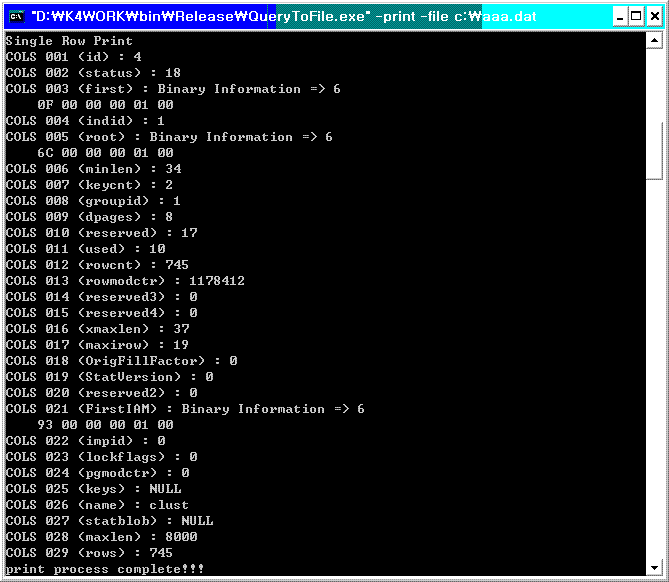
A. 위의 그림에서 보신바와 같이 테이블내에 혹은 수행된 쿼리 결과내에 여러개의 BLOB 형식의 데이터가 위치와 상관없이
삽입되어 있더라도 동작 수행에 문제는 없으며, 단 한 컬럼당 BLOB 데이터의 크기가 100MB 정도까지만 지원되도록
하는 제한 사항이 있습니다. (이는 일부러 제한을 둔것이 아니고, 아직까지 해결하지 못한 문제랍니다. -_-;;;)
B. 테이블을 백업하였을 경우는 테이블의 자료구조가 100% 정확하게 파일에 설정되지만, 쿼리의 수행결과를 파일로 저장할 경우는
select into 했을 때와 마찬가지로 호완가능한 구조로 저장되기 때문에, 테이블에 로딩했을 때 원본과 데이터 타입 일부가 다를 수
있습니다. 예를 들면 smallmony 타입을 쿼리 결과로 파일에 저장했을 경우 decimal 로 저장됩니다.
혹은 sysname 타입을 저장했을 경우는 nvarchar 로 저장되죠.
백업 기능을 이용 -BACKUP -TABLE sysindexes 로 저장한 것과
익스포트 기능을 이용 -EXPORT -QUERY "select * from sysindexes" 로 저장한 경우 테이블에 저장된 결과물은 동일하지만
테이블의 자료형이 일부 다를 수 있습니다.
반대로, -EXPORT 형태로 저장했을 경우는 해당 MSSQL 버전의 특정 자료형에 구속되지 않기 때문에 다른 버전의 MSSQL에도
테이블로 로딩할 때 별 문제가 없습니다. (2005에서 만든 파일을 2000에도 로딩시킬 수 있음)
C. 파일에 특정한 보안 로직이나 권한 제한등이 없기 때문에 외부로 유출되었을 경우 누구나 DB에 로딩 시킬 수 있습니다.
관리상의 주의가 필요합니다. (보완해야할 대표적인 기능중에 1번째)
D. 데이터파일에 대한 압축 기능이 제공되지 않습니다. (보완해야할 대표적인 기능중에 2번째)
(MSSQL 2008 버전 부터는 지원하다는데.. 아직 접해보지는 못했음)
2. 알려진 사용상의 장점
MSSQL에서는 DTS 및 패키기 매니저, BCP등을 지원하는데 이렇게 떨궈진 파일들은 실제로 DB에 넣어놓기 전까지는
내부 구조가 어떻게 생겨먹었는지, 무슨 이유로 만들어졌는지, 어떤 데이터가 들어있는지 아무도 모르죠..
본 프로그램을 이용해서 저장할 경우는
-PRINT 기능을 이용하여, DB에 로딩하지 않고서도 아래와 같이 필요한 정보를 볼 수 있습니다.
파일이 생성된 시각, 만들어질 당시 접속한 데이터베이스, 유저명(암호는 당연히 기록되지 않음), 수행한 쿼리 및 대상 테이블
각 컬럼의 구조 정보, 필요에 의해 기술한 코멘트, 그리고 첫번째 로우의 데이터 정보를 출력해줍니다.
(하기사 이것때문에 만든것입니다. 장점은 흠.. -_-;;; 이게 다군요..)
하나더 라고 한다면, 흠.. 쓸만할 만큼은 충분히 빠릅니다. GUI 툴처럼 복잡하지도 않고, BCP 처럼 다양한 옵션을 지원하진 않지만.
성능하나만은 탁월하게 빠르다고 말씀드릴 수 있겠네요. 파일로 떨구는거나 테이블에 밀어 넣는거나... ^^;;;
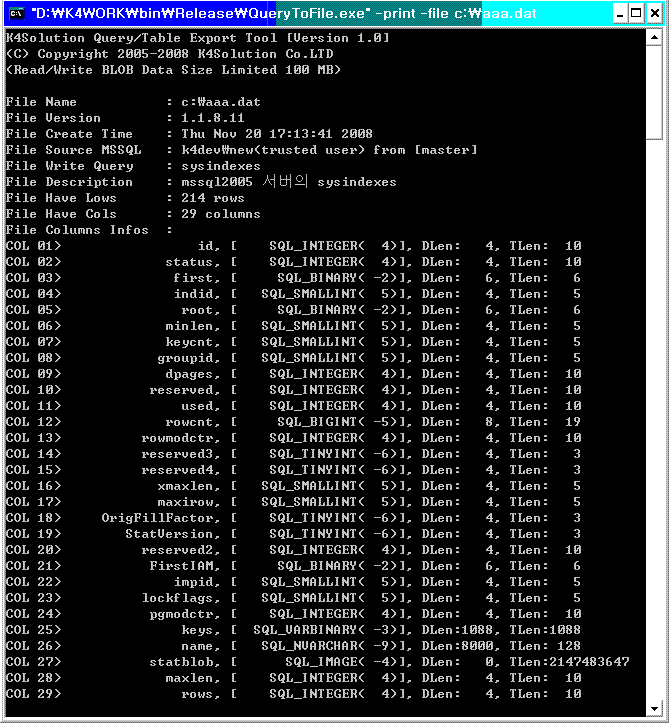
<이어진 화면>
위의 그림에서 처럼, 생성시 넣어준 정보와 간단한 디스크립션, 컬럼 정보 및 저장된 내용중 첫번째 데이터를 출력해 줍니다.
바이너리 및 이미지 데이터는 출력시 64바이트를 넘어가면 64바이트까지면 화면상에 출력해줍니다.
특별하게 설치할건 없고, 실행파일 하나와 DLL 두개로 구성되어 있어서 그냥 압축 풀고 사용하시면 됩니다.
<테스트환경: Windows 2003 Server 32Bit, Windows XP Home/Pro 32Bit, Windows Vista Home 32Bit, Windows 2008 Server 64Bit>
사용상의 문제점이나 활용 방안에 대한 의견이 있으시면 개발하는데 많은 도움이 되겠습니다. ^^;











 k4_freetds-stable.zip
k4_freetds-stable.zip